1
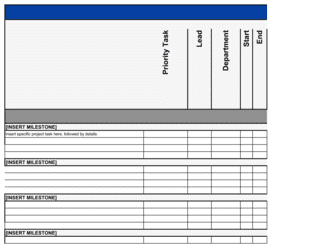
Define the plan scope and assign a plan owner
Identify which systems, locations, and business functions this plan covers. Name a single owner responsible for keeping it current and a backup owner. Record the version number and review date on the cover page.
💡 Scope creep is the most common DRP problem — be explicit about what is out of scope (e.g., physical security, HR continuity) to prevent confusion with adjacent plans.
2
Inventory all critical systems and assign criticality tiers
List every IT system, application, and data asset. For each, record whether it is on-premises or cloud-hosted, its owner, and its dependencies. Assign a Tier 1, 2, or 3 classification based on business impact if unavailable.
💡 Limit Tier 1 to systems whose failure would halt revenue or create a regulatory breach within 2 hours — most organizations have 3–6 genuinely Tier 1 systems.
3
Set RTO and RPO for each Tier 1 and Tier 2 system
Work with business stakeholders — not just IT — to agree on the maximum acceptable downtime and data loss for each critical system. Document the business justification for each target, not just the number.
💡 If stakeholders set an RTO of 1 hour for a system with no hot standby, flag the cost to achieve it — unrealistic RTOs are more dangerous than honest ones.
4
Document the recovery team with named individuals and contact details
List every recovery team role with the current person's full name, direct phone number, personal email, and a backup contact. Specify each person's responsibilities during an incident.
💡 Store the contact directory in at least two offline locations — a printed copy in the server room and a shared drive accessible without VPN — so it is reachable when systems are down.
5
Write step-by-step restoration procedures for each Tier 1 system
Break each system's recovery into numbered steps specific enough for a qualified substitute to execute. Include backup system access paths, credential vault references, verification checkpoints, and estimated time per step.
💡 Have a team member who did not write the procedure attempt to follow it cold — every point of confusion is a gap that will cost you during a real incident.
6
Document backup schedules, retention, and retrieval procedures
Record the backup frequency, storage locations (on-site and off-site), retention policy, and the exact steps to retrieve and validate a backup before using it in a production restore.
💡 Test backup retrieval and validation independently of a full DR test — many organizations discover corrupted or incomplete backups only when they need them.
7
Schedule and log all tests
Set a recurring calendar for quarterly tabletop exercises and an annual live failover test for at least one Tier 1 system. Log every test result, gap found, and remediation action with an owner and due date.
💡 Run the first tabletop within 30 days of finalizing the plan — waiting until the annual test date to discover gaps negates the plan's value.
8
Distribute the plan and confirm receipt
Send the finalized plan to every recovery team member and store copies in at least two accessible locations. Confirm that all team members have reviewed their specific sections and know where to find the plan offline.
💡 Require each team member to sign or digitally acknowledge receipt — acknowledgment creates accountability and surfaces individuals who have not actually read their procedures.